How does SpecLoR work?
SpecLoR works entirely during inference-time sampling. Click on each stage below to explore its mechanism.
Stage 1: Lookahead Projection
Diagnosing trajectory drift directly within the intermediate noisy latent space $z_t$ is intractable due to the dominance of timestep-dependent noise. To bypass this, we utilize the current predicted vector field $v_\theta(z_t, t)$ to project the state into a noise-free space via a single Euler step:
$$z_{t,0} = z_t - t \cdot v_\theta(z_t, t)$$This lookahead prediction $z_{t,0}$ acts as a diagnostic window, revealing early structural ambiguities before they solidify into physical artifacts.
Stage 2: Frequency Decoupling
Directly modifying the spatial representation of $z_{t,0}$ is challenging because global motion structures and fine geometric details are tightly coupled. We overcome this by shifting intervention to the frequency domain via a 3D Fast Fourier Transform (FFT) across $(T, H, W)$.
This transformation explicitly decouples the macroscopic energy (Amplitude $\mathcal{A}$), which is susceptible to trajectory drift yet safe to rectify, from the highly vulnerable, geometry-encoding Phase $\mathcal{P}$.
Stage 3: Amplitude Rectification
We rectify only the corrupted amplitude spectrum while keeping the delicate phase strictly locked. We propose two variants:
- SpecLoR-Zero: Utilizes a universal zero-cost global prior. Real-world videos exhibit a $1/f^\alpha$ power-law decay. We bound the amplitude within this natural variance envelope: $$\mathcal{A}_{rect} = \mathcal{A}_{curr} + \lambda \cdot (\mathcal{A}_{tgt} - \mathcal{A}_{curr})$$
- SpecLoR-Adapter: A lightweight context-aware DiT that predicts an instance-specific residual amplitude map $\Delta\mathcal{A}$ optimized via log-magnitude MSE.
Stage 4: Re-Noising & Inference
We recombine the rectified amplitude $\mathcal{A}_{rect}$ with the preserved phase $\mathcal{P}$, applying a 3D Inverse FFT to yield a purified clean anchor $\hat{z}_{t,0}$.
Finally, we integrate this corrected state back into the ODE solver by re-noising $\hat{z}_{t,0}$ to the current timestep $t$ using noise $\epsilon$:
$$\hat{z}_t = (1 - t) \cdot \hat{z}_{t,0} + t \cdot \epsilon$$This provides a structurally sound anchor for the subsequent flow matching trajectory.
SpecLoR Inference Pipeline
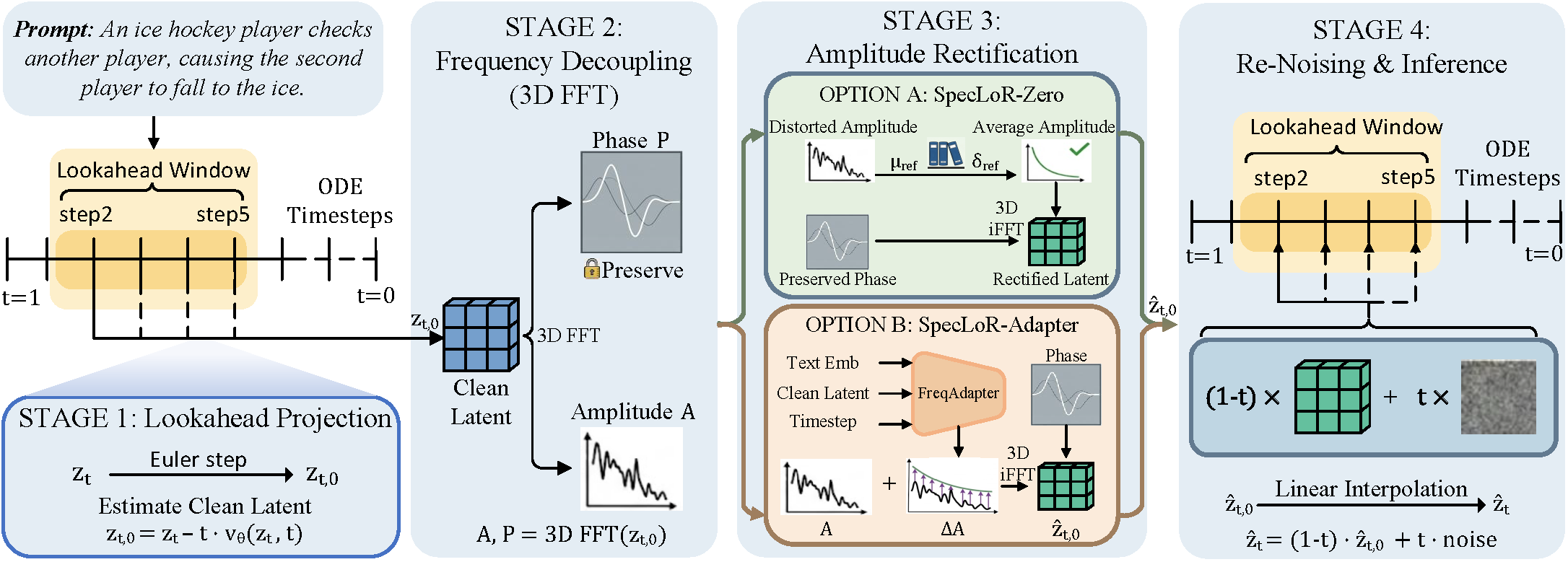
The noisy latent is projected to a clean lookahead state, transformed via 3D FFT, rectified in the amplitude domain, and re-noised back to resume ODE integration.